

1. 索引调度系统介绍
索引调度系统是基于airflow 开发的定时调度系统,对airflow进行封装,简化任务的配置及管理,调度系统的分布式功能使用celery。搜索的定时任务接近400个,分钟级的任务接近300个,预计后期会达到日调用接近100w次。因此调度系统如何保证高可用及后期的水平扩展至关重要。本文简要介绍下调度系统高可用的实现。
1.1 当前cron表达式的缺点
当前的定时任务配置在Linux Crontab 定时任务,主要存在以下缺点:
- 配置容易出错,不好管理
- 日志查看困难
- 水平扩展较难实现
- 大索引的分布式调度很难实现
- 任务失败告警定制比较复杂
- 增量任务的失败补偿机制缺失
- 。。。
1.2 调度系统主要解决的问题
调度系统能解决的问题就是同当前配置的cron表达式进行对比,能够解决的问题如下:
| 问题项 |
|---|
| 任务级别的失败重试,执行超时机制,单任务最大并发限制 |
| 支持手动触发任务 |
| 任务关闭 |
| 关闭一段时间后任务开启的执行逻辑 |
| 多台机器上任务的并行调度 |
| 增量任务的失败补偿机制 |
| 一个大任务里的多个子任务的间隔串行执行 |
| 支持灵活的任务分片规则 |
| 任务报警机制更加灵活 |
| 执行log页面化查看,执行结果可视化图表化 |
1.3 调度系统的架构
1.3.1 系统组件图
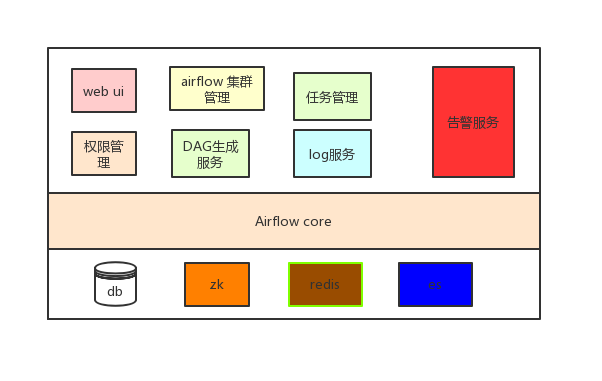
1.3.2 系统结构图
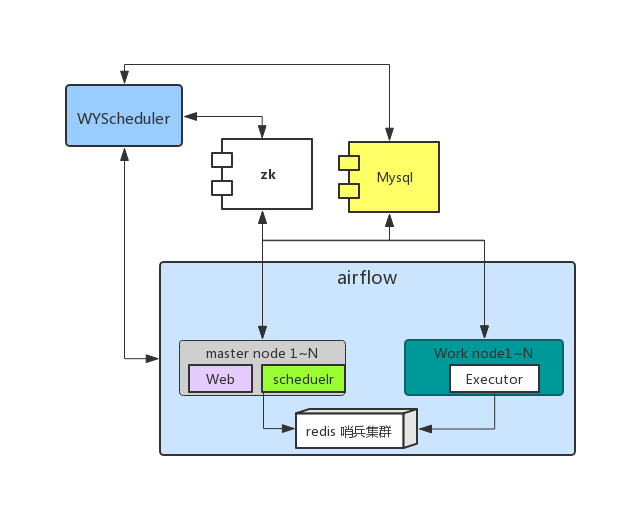
2.调度系统的高可用
2.1 调度器(master)高可用
索引调度系统的核心使用的是开源的airflow, airflow的调度器(master)节点是中心化的节点,即一个系统中只能有一个master节点。这显然不能满足高可用的需求。因此,我们结合zk对airflow的jobs.py进行改造,做到去中心化。
具体实现如下:
-
在调度器启动时,注册机器名及心跳时间到zk节点上,如下图所示:

-
修改airflow 的jobs.py中的create_dag_run方法
- 调度器调度任务时先从zk上获取可用的master节点(‘可用’ 即 当前时间 - 心跳时间 < 30)
- 把可用的master节点列表放到一个数据中,如:master_nodes = ['lx38', '1x47'];
- 对master_nodes列表进行排序,保证每个master看到的列表的完全相等
- master调度任务时;依据任务名计算hash值; task_hash_code = hash(dag.dag_id)
- 计算任务是否可用被当前master调度器调度 index = tash_hash_code % len(master_codes)
- 如果os.uname()[1] == master_nodes[index] 则进行调度,否则则直接返回,不进行任务的调度
具体代码实现如下:
@provide_session
def create_dag_run(self, dag, session=None):
self.zk_client.heart_beat()
hash_code = hash(dag.dag_id)
master_node = self.zk_client.get_master_node()
index = hash_code % len(master_node)
if len(master_node) > index:
print(index, dag.dag_id, master_node[index])
if master_node[index] != host_info.host_name():
return
if dag.schedule_interval and conf.getboolean('scheduler', 'USE_JOB_SCHEDULE'):
active_runs = DagRun.find(
dag_id=dag.dag_id,
state=State.RUNNING,
external_trigger=False,
session=session
)2.2 worker高可用
worker节点的高可用依据队列进行实现。如 我们在lx48 启动worker节点时指定消息队列名为bds, 在lx40上启动worker节点时指定消息队列名也是bds。那么lx48和lx40会消费bds队列中的任务,并且保证不会被重复消费。如果lx48机器挂掉或者不可用,那么由1x40消费所有bds队列中的任务,这样不会影响业务。
2.3 消息队列高可用
airflow的消息队列比较灵活,目前常用的是rabitmq及redis。airflow使用celery作为分布式任务调度,celery对于消息队列的支持使用的是AMQP协议,即任何中间件值用实现标准的AMQP协议,那么都可以作为airflow的消息队列进行使用。
消息队列我们使用的是redis。redis的集群模式使用的哨兵模式,一个master节点,两个slave节点。滨安机房一套,兴义机房一套。完全独立,实现双机房双活,由于redis是dba进行维护,对于消息队列的高可用不做高多的介绍。
2.4 数据库高可用
数据库我们使用的是mysql, 主要存放任务执行数据。数据库使用的是主从模式,通过VIP提供统一出口,由keepalived 保持主从之间的存活。由dba进行维护,不做详细的介绍
2.5 zk高可用
zk主要用来存放worker的心跳数据,master心跳数据,dag 任务元数据,master高可用节点信息。zk我们团队进行维护,搭建了滨安一套,兴义一套。主要是做双机房双活是使用。每个机房zk三个物理节点,在高可用上支持挂掉一个节点,后期为了更高的稳定性,准备新增zk物理节点为5个。
2.6 告警
告警主要有两类:分系统告警及业务告警。告警形式主要有短信告警,钉钉告警,邮件告警,后期也支持微信告警
系统告警:
| 告警项 |
|---|
| 磁盘io |
| cpu |
| 网络 |
| jvm |
| 中间件:redis,zk, mysql 监控 |
业务告警
| 告警项 |
|---|
| 任务失败重试邮件告警 |
| 任务失败短信告警 |
| 同一个任务名称累计超过5个在running状态则短信告警 |
| 一个任务执行时长超过配置的任务间隔时长则钉钉告警 |
| 一个任务执行时长超过配置的任务间隔10倍则短信告警 |
2.7 master及worker自动拉起
自动拉起顾名思义就是当master节点或者worker节点挂掉或者假死时不需要人工干预,能够自动重启,并且不影响调度功能。
- 我们的调度系统目前能够做到在master节点或者worker节点挂掉时能在10s能自动拉起;
- 在master节点或者worker节点假死时能够在35s内自动重启
2.7.1 master自动拉起实现:
- 心跳逻辑实现
修改airflow 的jobs.py的创建任务的逻辑 create_dag_run,这个方法被调度每隔2s调用一次,检测是否有符合条件的任务,进行调度。因此我们可以在这个方法中做调度器的心跳实现。具体代码如下:
@provide_session
def create_dag_run(self, dag, session=None):
"""
This method checks whether a new DagRun needs to be created
for a DAG based on scheduling interval.
Returns DagRun if one is scheduled. Otherwise returns None.
"""
# 做任务心跳逻辑;每隔2s往zk节点更新信息
self.zk_client.heart_beat()
...heart_beat()的代码如下:
def heart_beat(self):
date_str = str(datetime.now())
try:
# 心跳内容存放当前时间
self.zk.set(self.path, bytes(date_str))
except Exception as e:
self.logger.error(e)
finally:
# 写一份到文件
file_util.save_to_file(common_config.scheduler_heart_file, date_str.split('.')[0])心跳在zk的存储如下图:
-
master假死或down掉自动拉起
在调度系统启动一个进程,每隔15s检测一次master节点的心跳时间及master进程是否存在 如果 当前时间-心跳时间 > 35; 则kill master进程;然后重启 如果master进程不存在,则重启 -
第二点中的进程检测在索引调度系统中,如何保证索引调度系统不down掉及假死
在linux中配置每隔1分钟的cron表达式 */1 * * * * cd /home/qa/airflow/wyscheduler/alarm && ./heat_beat_cron.py scheduler >> /tmp/zhangxjairflow_worker.log 2>&1 &
2.7.2 worker节点自动拉起
心跳逻辑实现
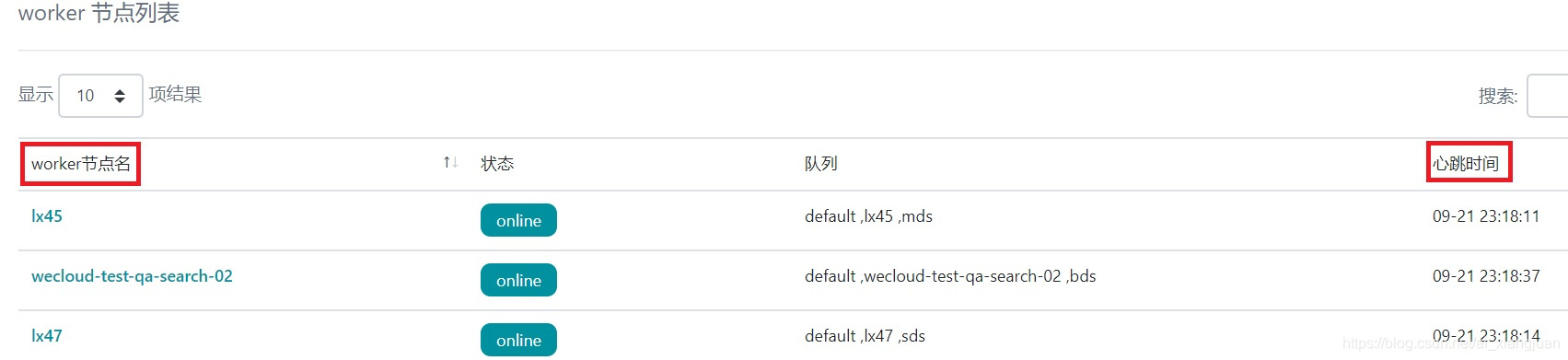
在索引调度系统给每个worker节点配置一个心跳任务;master每隔1分钟调度心跳任务在每个worker节点执行,worker节点执行成功更新心跳时间,心跳时间的存储在zk节点中。
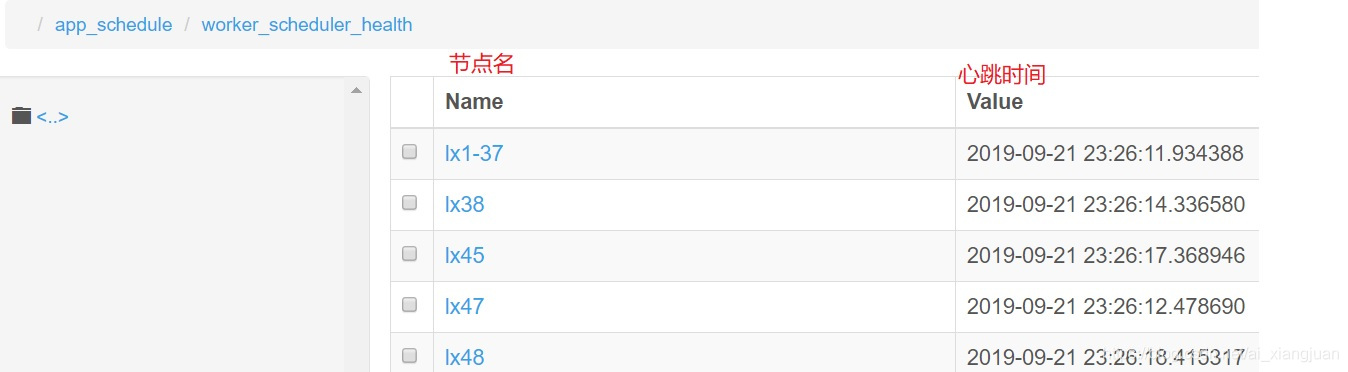
worker节点的心跳任务如下图:
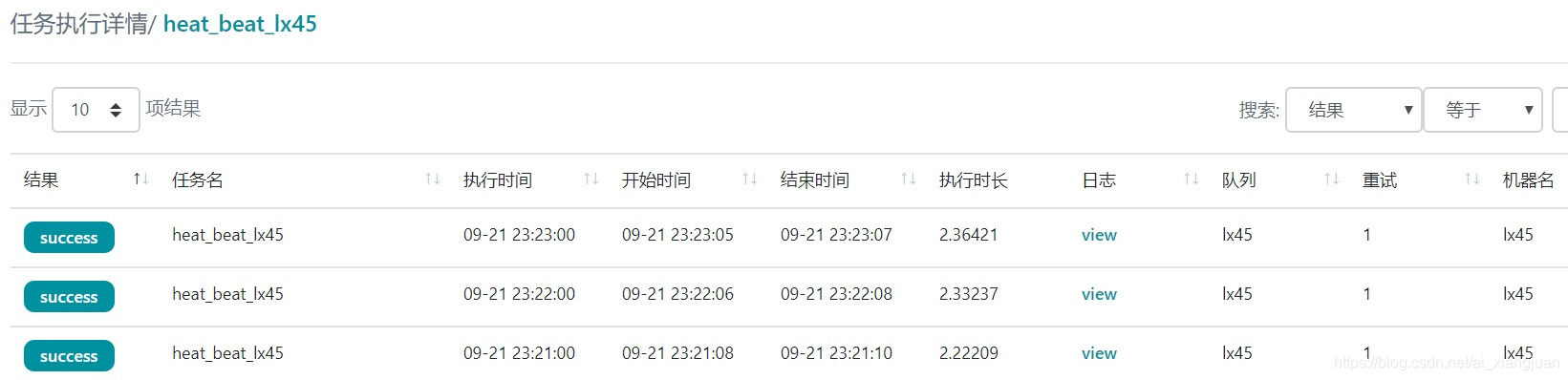
点击节点名,可以看到具体的心跳任务,如下图:
zk节点的心跳存储如下图:
-
worker假死或down掉自动拉起
在调度系统启动一个进程,每隔15s检测一次worker节点的心跳时间及worker进程是否存在 如果 当前时间-心跳时间 > 75; 则kill worker进程;然后重启 如果worker进程不存在,则重启 -
第二点中的进程检测在索引调度系统中,如何保证索引调度系统不down掉及假死
在linux中配置每隔1分钟的cron表达式 */1 * * * * cd /home/qa/airflow/wyscheduler/alarm && ./heat_beat_cron.py worker >> /tmp/zhangxjairflow_worker.log 2>&1 &2.8 任务失败重试
调度系统中的每个任务在失败时,可以进行重试,重试的次数支持自定义;
重试时支持延时多少秒进行进行重试,延时时间支持自定义。
2.9 僵尸任务处理
当worker节点被kill -9 或者物理机突然断电或者挂掉时,可能出现正在执行的任务变成僵尸任务一直存在。airflow 对于正在执行的任务,每隔10s更新一次任务的心跳时间(对应mysql 是更新job表中的latest_heartbeat)。
我们在调度系统启动一个每隔15s的定时任务,
定时检查running状态任务的latest_heartbeat,如果当前时间 - latest_heartbeat > 30;
则清除dag_run及task_instance中的记录,调度器会重新调度此任务执行。3. 未来展望
未来我主要从以下几个方面对系统进行改进:
- 对airflow的使用的celery进行改造,使worker消费任务时能够根据机器的负载,内存,磁盘,网络等进行动态消费,避免均匀消费时对机器的压力,使用的机器资源的利用最大化。
- 对airflow的调度器进行改造,使得对秒级任务的支持更加友好。