

前言
笔者为微医搜索开发工程师,在春节疫情期间深入参与搜索架构优化相关工作,对大数据量数据存储,搜索接口性能调优和搜索架构优化有自己独特的见解。在整理了搜索近几年的一些常用的优化手段后,撰写此文,希望能够对在从事相关优化工作的从业者提供一些启发。
为什么要进行搜索性能优化?
搜索引擎出现之初就跟性能有着扯不开的渊源,甚至ES官方就声明过,一切设计都是为了更快的搜索。当然,没有搜索引擎,很多查询操作也可以在关系型数据库里完成,但是像like这种查询一旦数据量达到千万级,那个速度绝对是不可接受的,正因为搜索引擎的存在,我们可以做到TB级数据搜索的毫秒级响应,但是,我们为此付出的代价也是高昂的,我们需要为要查询的数据提前构建索引,并将构建好的索引存储在内存里以实现100ms内的查询响应速度,而这些都需要硬件资源的支持。在如今少则8、9台服务器,多则几十台服务器的集群里,如何利用好我们有限的硬件资源以服务更多的业务,如何在不增加硬件资源的情况下优化慢调用,如何更合理的分配硬件资源等,都将为公司节约一大笔硬件和运维开销。
我们先问自己几个问题
1、为什么在不加干预的情况下接口性能会恶化?
2、性能优化的目标是什么?
3、搜索接口性能跟哪些方面有关?
带着疑问,我们继续分析下这几方面原因
1、为什么在不加干预的情况下接口性能会恶化?
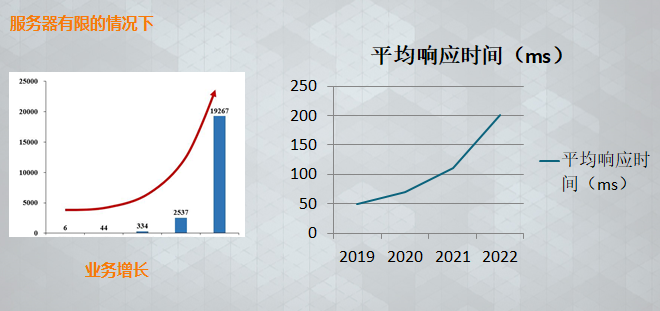
由上图我们可以看出
随着时间的增加,我们搜索引擎内接口存储的数据量也在增长,若不加干预,接口平均响应时间也是在增加的,这是因为数据量的增加导致我们索引和缓存已经对内存的需求都有明显增加。
而我们希望是这样的:
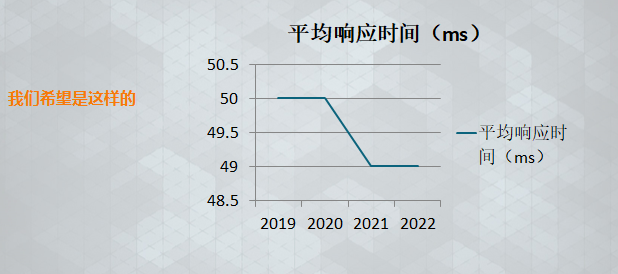
随着时间推移,接口性能没有恶化甚至还有所下降(没有增加或减少服务器资源的情况下)
当然这是一种理想情况,实际情况肯定会跟第一张图一样,而我们的工作就是尽可能的去实现理想情况的情形,即使是没有达到,至少能够避免性能恶化的速度过快。
而我们正是要解决这样一个主要矛盾,即:开发更加简单, 维护更加便捷, 使用更加省心, 查询更加迅速的搜索系统的需求与开发周期长, 业务更加复杂, 系统更加庞大, 数据量持续增长之间的矛盾。
其本质是:利用有限的资源,实现效益的最大化。
2、性能优化的目标是什么?
接口维度的 衡量指标:
1、全局指标:平均响应时间
2、可用性指标:1秒超时率
3、优化维度-过程指标:
300ms超时率,3秒超时率
索引维度:
索引量,索引磁盘占用大小,索引更新频率
3、搜索接口性能跟哪些方面有关?
索引:存储空间,数据量
请求量:qps( 并发能力)
查询复杂度
数据网络传输(带宽)
磁盘io(内存-磁盘数据交换)
缓存: 搜索引擎缓存,linux cache
JVM:gc停顿
而这些指标的收集就需要我们在监控能力上多下功夫,没有这些指标,性能优化就无从谈起,在出现一些线上问题的时候我们也会无从下手。
TIPS整理
这一章我们从几个层面去探讨搜索相关优化,这里我根据我们目前的搜索架构将整个数据链路抽象为几个层次,分别为:业务层,网关层,服务层和搜索引擎四个层次,在索引上还包括索引层,针对每个层次进行整理,这里主要以solr为例。
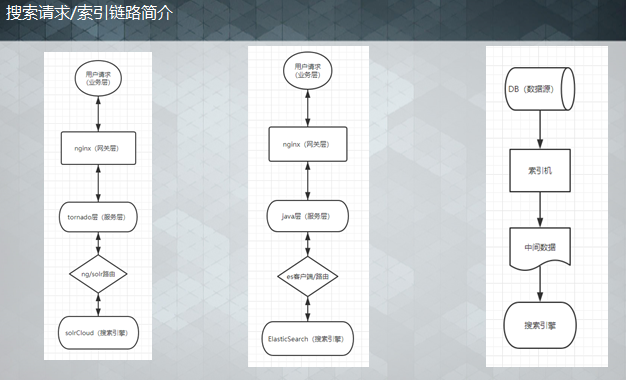
服务层优化
单次请求应尽可能减少耗时操作,即尽可能减少传递给solr的复杂查询(主要维度网络,查询复杂度)
1、fl只需返回需要使用的字段,避免fl=*或fl=全部可返回字段;
2、多与业务方沟通,避免不需要的聚合操作(group、facet等);
3、减少复杂的functionQuery(能不用就不用),必要时可利用索引阶段构造相关字段,以索引空间换接口时间;
4、多条件组合查询,特别是排除类的(-field1:xxx OR -field2:uuu 这种),可利用索引空间换接口时间,即将这几个筛选条件组合为索引中的1个字段,在接口查询时只筛选该字段即可;
示例:admin_doctor_consult接口的admin=0条件原先就包含(-doctor_user_id:0 AND policlinic_id:20161208002 AND -source:(846 OR 928 OR 423...))等条件,平均响应时间约400ms,因此将这几个筛选条件组合,在索引阶段聚合为no_shield字段,值为0/1, 接口admin=0时筛选no_shield=1即可,平均响应降至50ms;
5、尽量不使用动态查询,例如动态排序,bq动态加权等 计算能在索引阶段完成尽量放在索引层
6、通用缓存机制优化——多用于实时要求不高的场景
7、通过压测等手段确定服务层qps,避免服务层吞吐量成为搜索引擎瓶颈
8、对于solr而言,leader节点往往索引压力更大,负载更高,需要在网关上进行剔除,当然具体实现方式有很多种
总结:服务层优化,我们的关注点在查询逻辑是否高效,吞吐量上限以及请求转发链路上的耗时
搜索引擎层优化
1、适当调大solrconfig.xml中filterCache配置模块的autowarmCount数量,对FastLRUCache可以开启cleanupThread="true";对于实时性要求较高的collection,可调整属性useColdSearcher=true;
调整缓存后跟踪缓存命中率,和预热时间以及线上超时情况,确保调整符合预期

经实测,加缓存后接口容量(QPS)至少提升3倍
2、分片
针对数据量较大的collection,如果聚合类的查询较少,可考虑进行数据分片,结合具体服务器数量,可分2个及以上分片(尽量避免同一collection的多个分片存在重复的服务器);
分片方式:
1、根据主键id做一致性hash分片;目前solr cloud集群的分片全是这种(副作用,平均响应时间会提高)
2、根据指定字段做一致性hash分片;(只查一个副本,消除副作用影响)
3、冷热数据:使用多个collection,区分冷热数据,如索引分近一个月和全量数据,全量数据还可以按年分隔。
ElasticSearch冷热节点架构

热节点:
1、近期数据,热数据,
高实时节点,
配置相对较高,
例如:固态硬盘节点
2、冷数据节点
历史数据,全量数据节点
使用节点角色进行auto route
4、优化solr jvm 减少gc停顿时间
有助于优化300ms超时率和系统recovery问题 方向主要是调大jvm和优化jvm内存占用优化内存占用:
优化fieldcache内存占用,将排序&查询&聚合字段设置为 docvalue,减少这部分内存
调整jvm cms阈值CMSInitiatingOccupancyFraction=70 避免过早进行fullgc 提高jvm内存利用率
使用g1 gc
5、一些小技巧:
- 范围时间查询使用Tdate字段 有助于加速查询( TrieDateField出生于 Solr4.x之后,6.5版本以上已经统一为更快的DatePointField类型)
- 减少ngm分词使用,原则:能不分词不用ik 能用ik不用edg 能用edg不用ngm
- 不查询字段index=false,不展示字段 store=false
- (es 同样index=false ,但是展示是修改_source notinclude,es默认store=false)
- 。。。
这些操作可能几个字段没什么影响,积累多了就是个量变到质变的过程。
在这些小技巧里,solr的fq合并效果尤为显著,操作方式也比较简单,就是将所有fq操作合并到一个fq里,原理是减少fq的merge操作。
我们有几个接口采用这个方式后实现了平均响应时间从200ms到20ms的质变。
7、在一些大数据量实时场景下,使用ES也是一个方向,针对哪些场景适合用solr哪些适合用es的这块的调研我们还在继续,从效果上来看,部分接口从solr迁移到es表现出了不错的效果,当然也有例外。
索引层优化
索引层优化主要考虑的是索引间互相影响,主要是索引阶段影响,一个大型索引几乎会对整个集群都造成影响,原因是对linux cache的需求会导致查询热数据被挤占,从而影响其他接口查询。
对于微医大部分业务,对搜索引擎压力最大的不是查询,而是索引,因此索引的优化对查询性能提升至关重要,在索引创建期间,对linux cache,磁盘io,cpu和带宽均有比较高的使用率,jvm表现为gc频繁,同时频繁的索引创建对搜索引擎缓存刷新,段合并和索引分发造成直接影响,搜索接口表现为qps下降和超时率上升,并且存在集群间互相影响。
优化的主要方向为
1、去全量,改为支持按天增量构建
2、冷热数据分离
3、大型索引错峰创建,夜间创建
4、增量/全量构建需分页构建,每页大小适当,尽量避免一页10000以上,同时调整并发提交线程数)进行控制索引提交频率,进而控制全量索引速度,可以结合solr jvm监控进行调整,以jvm的gc平稳下进行索引构建为目标
5、目前索引构建软提交时间默认全量15s,增量1s,秒级增量1s,实时500ms,可适当调大该配置,特别是手工进行全量构建或增量构建场景
6、避免使用分词较为复杂的分词器,如ngm,以及减少长字段的分词,避免一个字段长度过长,产生严重的io开销
我们也在尝试一些革命性的索引方式,如
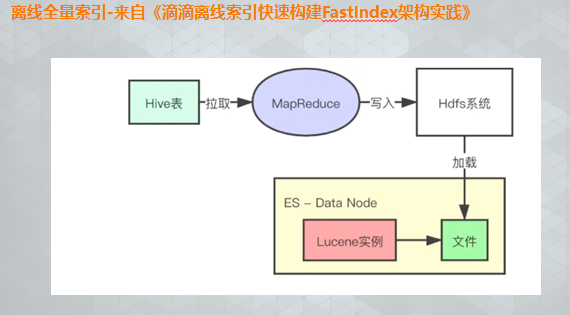
详见这篇文章https://xueqiu.com/9217191040/144360507
以及es+hbase的架构
比如说你现在有一行数据。id,name,age .... 30 个字段。但是你现在搜索,只需要根据 id,name,age 三个字段来搜索。如果你傻乎乎往 es 里写入一行数据所有的字段,就会导致说 90% 的数据是不用来搜索的,结果硬是占据了 es 机器上的 filesystem cache 的空间,单条数据的数据量越大,就会导致 filesystem cahce 能缓存的数据就越少。其实,仅仅写入 es 中要用来检索的少数几个字段就可以了,比如说就写入es id,name,age 三个字段,然后你可以把其他的字段数据存在 mysql/hbase 里。
hbase 的特点是适用于海量数据的在线存储,就是对 hbase 可以写入海量数据,但是不要做复杂的搜索,做很简单的一些根据 id 或者范围进行查询的这么一个操作就可以了。从 es 中根据 name 和 age 去搜索,拿到的结果可能就 20 个 doc id,然后根据 doc id 到 hbase 里去查询每个 doc id 对应的完整的数据,给查出来,再返回给前端。
写入 es 的数据最好小于等于,或者是略微大于 es 的 filesystem cache 的内存容量。然后你从 es 检索可能就花费 20ms,然后再根据 es 返回的 id 去 hbase 里查询,查 20 条数据,可能也就耗费个 30ms,可能你原来那么玩儿,1T 数据都放es,会每次查询都是 5~10s,现在可能性能就会很高,每次查询就是 50ms。
业务层优化
业务层优化重点是对业务进行瘦身,对系统进行减负以及纠正错误的业务使用方式:
例如:
1、错误使用创建时间范围进行分页数据限制。为了避免翻页时增加数据导致分页位置错误,业务方在入参内加入创建时间范围限制新增数据,而范围查询是一种比较慢的查询,这种场景如果不存在跳页我们一般建议走深分页
2、业务方定时任务更新数据表,而我们对该表进行了增量监控+实时监控
正确做法:推动业务方改造定时任务,对定时任务更新数据进行打标,实时更新时忽略此部分更新,走增量更新
3、秒级增量分时段配置,夜间调用较少时停止更新
4、单次更新数据量过大抛弃
5、减少接口多次调用和solr的多次查询:
6、提前与业务方沟通,了解业务方的业务流程,提供调用请求示例,避免业务方不了解搜索从而进行的多次查询;
7、提醒业务方减少fl字段的取值,以及避免放开一次返回大量数据的限制,从而减少io开销;
8、将查询阶段的复杂逻辑放到索引层去做,例如:走离线计算,分组聚合型查询进行接口维度拆分等
总结
考虑到笔者经验的限制,以上所述肯定不是搜索优化的全部,但是肯定是经过实战验证过的有效方法。为了这个目标:利用有限的资源,实现效益最大化,我们也应该建立一套执行策略:
实现路径:
1、完善监控,建立健全资源评估方式和路径
2、对搜索技术优化建立标准化,流程化,规范化的系统,工具和文档
3、持续优化,及时反馈
作为一名开发人员,应明确:
1、掌握技术的深度,避免成为一名“用户”
只有对你所使用工具有足够的了解,才能做到资源的合理分配
2、在日常开发中具备优化意识,把优化作为一个日常的工作,而不是阶段性的工作,同时避免“前人挖坑后人埋”
3、斤斤计较,坚持不懈,死磕到底
性能优化是一个没有终点的道路,而目标只有一个,为了极致的性能,永不停息!